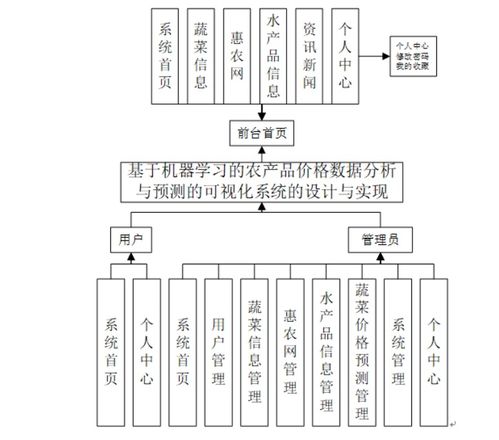
基于機器學習的農產品價格數據分析與預測的可視化系統的設計與實現
隨著信息技術與農業經濟的深度融合,利用數據科學方法洞察市場規律、輔助決策已成為現代農業發展的必然趨勢。本文旨在探討一個集數據采集、智能分析、價格預測與交互式可視化于一體的計算機系統服務的設計與實現方案。該系統以機器學習為核心,旨在為農戶、經銷商、政策制定者及消費者提供一個直觀、精準的農產品價格分析與預測平臺。
一、 系統總體設計
1. 系統目標與架構
本系統的核心目標是實現農產品價格數據的動態采集、存儲、分析、預測與可視化呈現。系統采用分層架構,自下而上包括:
- 數據層:負責從多渠道(如政府公開數據庫、大型農產品交易市場API、網絡爬蟲等)采集歷史與實時價格數據,并進行清洗、整合與存儲,構建高質量的數據倉庫。
- 算法與模型層:這是系統的智能核心。利用機器學習算法(如時間序列分析(ARIMA)、回歸模型、集成學習(如隨機森林、梯度提升樹)乃至深度學習模型(如LSTM循環神經網絡))對處理后的數據進行訓練,構建價格預測模型。該層還包含特征工程、模型訓練、評估與定期更新的完整流水線。
- 服務層:提供數據分析與預測的API接口,封裝模型調用邏輯,為上層應用提供穩定的數據服務。
- 應用與可視化層:面向最終用戶的Web或移動端交互界面。通過圖表庫(如ECharts、D3.js)實現數據與預測結果的可視化,包括價格走勢折線圖、地域分布熱力圖、品種對比柱狀圖、預測區間展示以及關鍵影響因素分析圖等。
- 關鍵技術選型
- 數據處理:使用Python的Pandas、NumPy進行數據清洗與處理。
- 機器學習框架:采用Scikit-learn、TensorFlow或PyTorch構建和訓練預測模型。
- 后端服務:基于Flask或Django等框架開發RESTful API。
- 數據存儲:使用關系型數據庫(如MySQL/PostgreSQL)存儲結構化數據,并結合時序數據庫或NoSQL數據庫(如InfluxDB/MongoDB)處理高頻時間序列數據。
- 前端可視化:結合Vue.js或React等前端框架與專業化圖表庫開發展示界面。
- 部署與運維:考慮使用Docker容器化技術實現微服務部署,確保系統的可擴展性與可維護性。
二、 核心功能模塊實現
1. 數據采集與治理模塊
設計可配置的數據爬蟲與API對接程序,定時獲取多源異構數據。建立嚴格的數據清洗規則,處理缺失值、異常值,并進行數據標準化,確保輸入模型的數據質量。
2. 機器學習預測模塊
這是系統的核心算法模塊。實現流程包括:
- 特征提取:從原始數據中提取影響價格的關鍵特征,如季節性因素、節假日效應、市場供需量、相關品價格、宏觀經濟指標等。
- 模型訓練與選擇:針對不同農產品(如蔬菜、水果、糧食)的特性,試驗多種機器學習模型,通過交叉驗證、均方誤差(MSE)、平均絕對百分比誤差(MAPE)等指標評估性能,選擇最優模型或模型組合。
- 預測與更新:系統支持短期(如未來7天)和中長期(如未來季度)預測。模型需定期用新數據重新訓練,以適應市場變化。
3. 交互式可視化模塊
開發直觀的用戶儀表盤,主要功能包括:
- 多維數據探索:用戶可按時間范圍、地理區域、農產品品種等維度篩選和查看歷史價格走勢。
- 預測結果展示:以清晰的可視化形式(如帶有置信區間的預測曲線)展示未來價格走向,并提供關鍵數據點的解讀。
- 對比分析:支持不同品種、不同市場間的價格對比分析。
- 影響因素洞察:通過特征重要性排序等可視化手段,揭示影響價格的主要驅動因素。
- 數據導出與報告:允許用戶將圖表和數據導出,生成簡要分析報告。
三、 系統服務價值與展望
本系統的實現,作為一項專業的計算機系統服務,能夠將復雜的機器學習預測結果以直觀易懂的方式交付給用戶,顯著降低數據使用的技術門檻。其價值體現在:
- 對生產者與經銷商:提供市場預判,輔助制定種植、倉儲和銷售策略,規避風險。
- 對政策制定者:提供宏觀市場洞察,為穩定農產品供應、制定調控政策提供數據支持。
- 對消費者與研究機構:增加市場透明度,并為相關研究提供數據與分析工具。
系統可進一步集成更多數據源(如天氣、物流信息),引入更先進的機器學習模型(如注意力機制、圖神經網絡以捕捉地域關聯),并探索個性化推薦、價格預警等增值服務,從而構建更加智能化、前瞻性的農業決策支持生態系統。
如若轉載,請注明出處:http://www.xoxn.cn/product/17.html
更新時間:2026-05-12 05:11:29